« Les données de la recherche sont la matière première de la connaissance. Les partager, c’est ouvrir de nouvelles perspectives scientifiques », Frédérique Vidal, Ministre de l’Enseignement supérieur, de la Recherche et de l’Innovation (Juillet 2018)
Les données
L’axe des données est une approche complémentaire et moins souvent explorée que celle, plus évidente, du matériel ou du développement logiciel. Cependant, le matériel et le logiciel ne sont là fondamentalement que pour servir à la manipulation des données. Les données d’observation, les données produites (données médicales, simulations scientifiques numérisations, œuvres cinématographiques ou musicales, livres, photos) sont les principales sources que l’on peut citer. En informatique, la donnée est la représentation d’une information et sans données, il est impossible d’analyser notre environnement. Nous sommes des machines à traiter de l’information et donc des données, et nos machines et les logiciels qui les accompagnent ont été développés dans ce but.
Importance de la donnée
- La donnée est précieuse, utile et unique (trace d’un instant révolu). Cependant, la « valeur » de la donnée reste subjective et dépendante de l’usage et de l’usager. Mais l’histoire montre que la connaissance donne de nombreux avantages.
- La donnée « brute » (issue de l’observation) est souvent inutilisable. Elle
doit être traitée, analysée, interprétée, associée à d’autres éléments (méta
données) qui la rendent utile et utilisable, pérenne, échangeable pour des prises de décisions ou une meilleure connaissance. - Son acquisition (campagnes in situ, satellites, nombreuses heures de
calcul, instruments médicaux, sondes sous-marines, etc…) est en général
coûteuse, tant écologiquement que financièrement. - Son « exploitation » crée de la connaissance, de la « richesse » ou de la
« valeur ajoutée » et les entreprises se battent pour récolter de la donnée. Et nous sommes aujourd’hui face à une avalanche ininterrompue de données….
Coût environnemental des données
Il existe un concept central autour de la donnée qui s’appelle le cycle de vie des données.
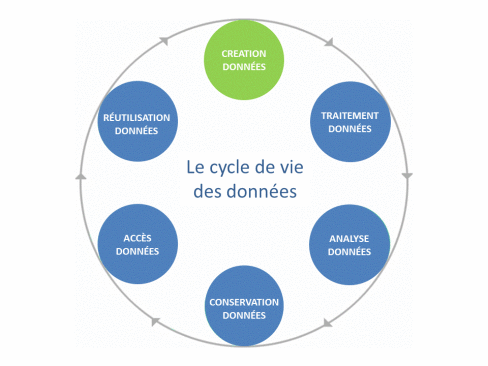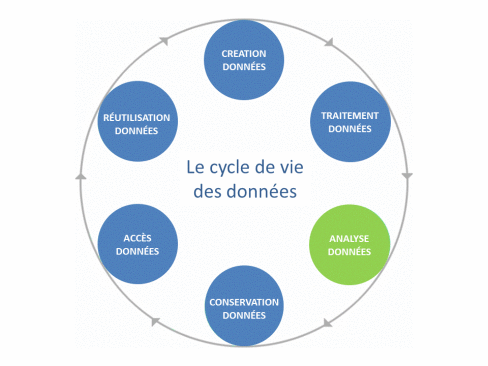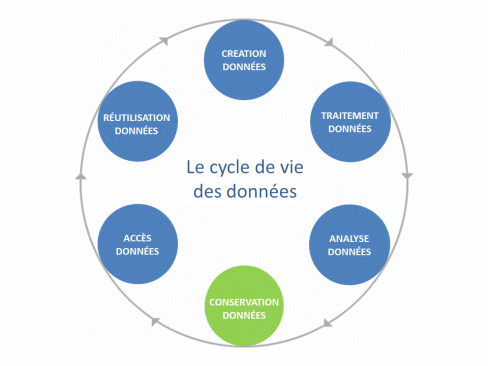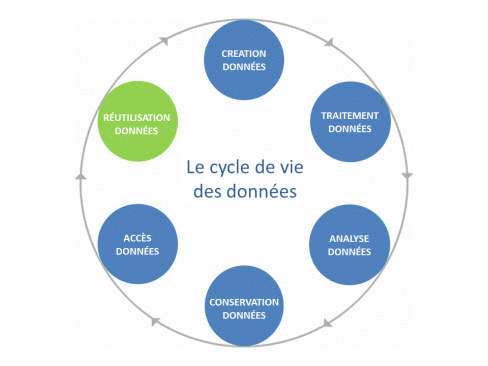
Chaque phase du cycle de vie introduit ainsi son propre coût : stockage, transport sur les réseaux, manipulation avec les ordinateurs, sauvegarde et enfin, archivage de long terme, etc, etc.
Dès l’instant ou on aura validé que la donnée produite ou acquise mérite d’être conservée (la première bonne démarche environnementale étant celle de ne pas produire ni conserver de données inutiles), il va falloir tout au long de son cycle de vie se poser les bonnes questions pour minimiser les impacts environnementaux voire sociétaux, la donnée pouvant être une source importante de manipulation de l’information (« fake news ») mais aussi servir pour la surveillance des individus ou de moyen de pression.
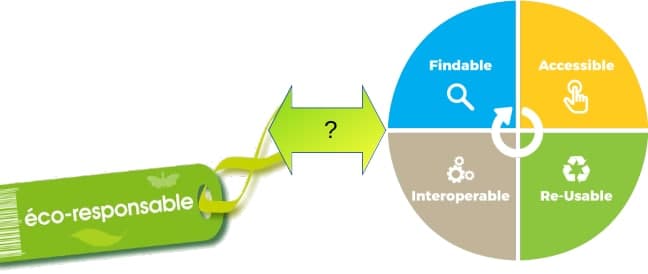
Le premier coût environnemental de la donnée est lié à son acquisition : campagnes de terrain scientifique, bateaux, satellites, envoi de sondes spatiales ou production (œuvres culturelles au sens large, simulations numériques, modélisation climatiques, etc…). Cette acquisition ou cette création de donnée a donc dès l’origine un coût environnemental important et il serait indécent de ne pas être attentif à conserver cette donnée bien souvent unique et précieuse. Il faudra pour cela agir dans un esprit orienté Open Science et FAIR (data Findable, Accesible, Interopeable, Reusable) qui met en place les bases d’une bonne gestion des données. C’est donc la démarche principale à mettre en place avant toute autre considération une fois la donnée acquise ou produite. Cette démarche est à la fois garante de la pérennité des données mais aussi, d’une certaine manière, la garantie que le coût environnemental de leur acquisition n’a pas été vain. La démarche FAIR n’est pas en soi particulièrement éco responsable, (voire même introduit un surcoût environnemental) mais elle permet plutôt de garantir que le coût environnemental initial d’acquisition ne l’aura pas été en pure perte. Les données seront ainsi associées à leurs méta données et à un plan de gestion de la donnée (ou DMP pour les anglo saxons) qui garantira le process optimal et la réflexion nécessaire à la bonne pratique de leur gestion.
Analyse et Traitement des données
à ces étapes du cycle de vie de la donnée, il faudra se montrer particulièrement attentif à plusieurs éléments qui auront de nombreux impacts environnementaux si on ne les prends pas en compte correctement :
- Conserver la donnée dans des formats de fichiers Ouverts et Interopérables. Il est particulièrement crucial d’être attentif à ces aspects pour éviter d’avoir à manipuler et convertir de manière inutile la donnée entre différents formats. De même, l’utilisation d’outils ouverts (Open Source) permettant de lire ces formats sera privilégié. Ces choix seront parfois fonction de la thématique professionnelle (Par exemple, CSV ou NetCDF)
- Il faudra se montrer attentif également à conserver la donnée au plus près de son usage. Si la donnée doit être manipulé pendant une certaine période, il sera beaucoup plus cohérent environnementalement parlant de conserver la donnée sur les machines qui serviront à l’exploiter, le coût de transport de la donnée sur les réseau informatique étant particulièrement élevé et fonction de la distance que les données auront à parcourir.
Conservation de la donnée
En ce qui concerne l’archivage de la donnée, on pourra se tourner (sans exhaustivité aucune ici) vers le CINES, l’infrastructure de recherche Data Terra ou le TGIR Huma-Num qui permettent de mettre en place les éléments indispensable à une gestion propre d’un archivage à long terme qui permettra également de d’assurer la dernière étape du cycle de vie : la réutilisation des données. Là aussi, on privilégiera les format ouverts et pérennes de toute manière la plupart du temps imposés par les sites d’archivage officiels.
Transport des données
L’infrastructure planétaire permettant l’interconnexion des centres de données est extrêmement complexe. Il faut savoir que 99% des données intercontinentales passent par des câbles sous-marins. Plus de 100.000 kms de câbles sont posés chaque année. En 2018, il y avait plus de 1.2 millions de kilomètres de câbles au fond de nos mers. Sans compter les infrastructures terrestres, antennes terrestres (2,3,4, et 5G ou faisceaux hertziens spécifiques), ou les infrastructures spatiales qui elles aussi sont utilisées pour le cheminement des données. Le coût environnemental du transport de la donnée est donc extrêmement complexe à estimer. Les fourchettes sont larges (Source : Electricity Intensity of Internet Data Transmission: Untangling the Estimate) et vont de 0,02 kWh/Go transportés à plusieurs dizaines de kWh/Go, avec plus probablement une fourchette réelle entre 2 et 6 kWh/Go. Une chose est certaine, ce coût n’est pas nul et la croissance exponentielle du trafic de données entraîne aujourd’hui une augmentation de la consommation des ressources nécessaires pour les traiter : machines, logiciels, réseau, … L’infrastructure croît pour absorber un volume de données toujours en augmentation. Le Big Data n’est pas plus virtuel que le nuage informatique et se concrétise en datacentres, en serveurs, en climatisation, en câbles optiques sous-marins et terrestres, en énergie à chaque étape de la fabrication et de l’usage (et même du recyclage) mais aussi en mines de métaux et de charbon (et donc, en pollutions irrémédiables de l’air, des sols et de l’eau) pour pouvoir traiter cette avalanche de données : 29To publiés chaque seconde en 2018….
Comment agir pour les données ?
Il existe plusieurs axes d’actions au niveau des données :
- Ne pas produire de donnée inutiles (Sobriété)
- Lorsque les données sont produites, appliquer à chacune des étapes de son cycle de vie des principes éco-responsables dictés par des logiques de science ouverte et de principes FAIR. Cela nécessite une certaine réflexion en fonction du contexte :
- En phase d’usage, minimiser la distance à parcourir sur les réseaux entre l’usage de la donnée et son stockage
- Utiliser les ressources de stockage/archivage/sauvegarde les plus éco-responsables possibles et adaptées aux volumes concernés,
- Appliquer les principes FAIR (formats standards ouverts et interopérables, données accessibles aux autres, donnée identifiée avec des métadonnées utilisables et normalisées)
- Appliquer enfin les principes de la Science Ouverte (qui s’appuie également sur les principes FAIR) pour permettre une large utilisation de ces données chèrement acquises et rendues disponibles.
- Utiliser les réseaux de transports les moins polluants. Les voici par ordre de pollution croissante : le filaire, le wifi et les réseaux Data de la téléphonie mobile (2/3/4/5/6G) avec des facteurs de 10 à 100 parfois en terme de consommation énergétique entre ces différentes pratiques.
- Se former et s’informer autour des bonnes pratiques de la gestion des données et intégrer les principes de sobriété sur les ressources utilisées pour manipuler, exploiter et stocker ces données en fonction du domaine d’utilisation (les pratiques peuvent êtres différentes en SHS ou dans les sciences dures par exemple).
- Limiter les redondances, se montrer critique sur les données à conserver, connaître et appliquer les bons principes de sauvegarde et d’archivage sur les données froides et chaudes.
Pour en savoir plus
Pour bien agir, il faut s’informer et connaître le sujet sur lequel on cherche à minimiser nos impacts environnementaux. Nous vous proposons ainsi une liste non exhaustive de liens institutionnels (ou non) pour aller plus loin autour de ces aspects du traitement de la donnée, de la Science Ouverte et des principes FAIR(E) :
- Site Ouvrir la science
- Archivage de la donnée : le CINES
- le réseau SIST (« Séries Interopérables et Systèmes de Traitements« ) qui traite de la chaîne de traitement des données de la recherche pourra également vous aiguiller vers ces thématiques et les bonnes pratiques autour de la gestion des données.
- Formats ouverts et recommandation de l’état : le RGI, version 2.0
- Licence de publication des données et Science Ouverte : la licence Etalab
- Exemples d’ACV sur les disques durs (SSD et HDD) par Seagate
- Cartographie des câbles sous marins à travers la planète
- Les principes FAIR
- Research Data Alliance (RDA)
- Réaliser un plan de gestion de données “ FAIR ” : Le site d’OPIDOR, DMP (CNRS), IRD
- En SHS, vous pouvez vous rapprocher du TGIR Huma-Num
- En sciences de l’Univers, Data Terra est un bon point d’entrée également
- Transport de la donnée :