
Cet article se focalise sur la consommation énergétique due à la phase d’utilisation des équipements. Pour une discussion plus générale des impacts de l’IA, voir l’article sur les impacts environnementaux de l’IA. Nous prendrons comme cas d’étude les processus d’apprentissage profond supervisés offline.
L’objectif d’un tel processus est d’apprendre à prédire une valeur à partir de données annotées. Pour donner un exemple concret aux personnes qui ne seraient pas familières du domaine, imaginons que nous souhaitons apprendre à reconnaître des images contenant un chat. Nous partirons d’une base d’images dont nous savons déjà si elles ont ou non un chat grâce à une annotation humaine par exemple. Ces images seront séparées en une partie qui permettra d’apprendre le modèle (données d’entraînement), et une partie qui permettra d’évaluer les performances du modèle (données de test).
Consommation d’énergie due aux programmes d’apprentissage profond
Les modèles d’apprentissage profond sont basés sur des réseaux de neurones à plusieurs couches, qui apprennent à représenter des informations de haut niveau d’abstraction des données. Un processus classique d’apprentissage profond supervisé est le suivant :
- choix de l’architecture du réseau en fonction de la tâche à accomplir;
- entraînement de plusieurs modèles permettant de les tester et d’optimiser les paramètres;
- test de chaque modèle sur d’autres données, qui vont permettre d’évaluer leurs performances réelles.
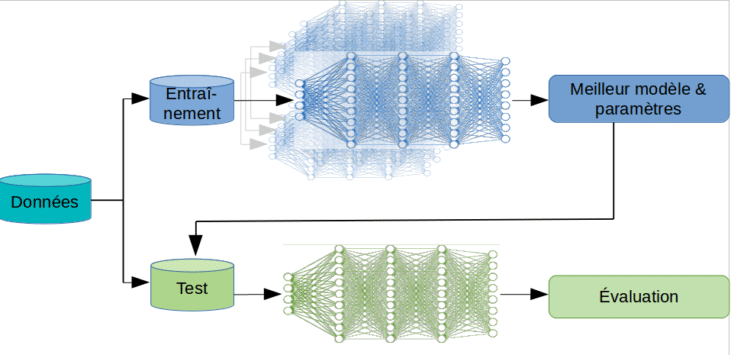
Bien que ces modèles fournissent des résultats qui présentent généralement une meilleure performance fonctionnelle que d’autres types de modèles, il est important de poser la question de leur coût énergétique. Ces processus sont souvent assez coûteux d’un point de vue énergétique, en particulier pendant la phase d’entraînement, qui peut durer plusieurs jours. Plusieurs facteurs vont influencer le coût énergétique du processus :
- la taille des données: pour bien fonctionner, un réseau profond nécessite une immense quantité de données étiquetées comme base d’apprentissage (pour le traitement d’images, cela se compte souvent en millions, ce qui fait qu’il est difficile de les utiliser par exemple en diagnostic médical, faute de nombre d’exemples suffisants);
- l’architecture du réseau: plus l’architecture du réseau est complexe, plus il sera long à entraîner;
- le type de tâche: plus la tâche est de haut niveau, plus le processus sera long;
- les décisions d’optimisation des paramètres ; en effet, l’un des problèmes de ce type de méthodes est qu’il est n’est pas simple de trouver un critère d’arrêt et il est donc fréquent de laisser tourner un programme plusieurs jours pour voir si le système s’améliore. En outre, l’explicabilité des modèles étant actuellement faible (il est difficile de comprendre les résultats), beaucoup d’utilisateurs procèdent par essai-erreur, en essayant plusieurs architectures de réseau par exemple, ce qui peut générer des expérimentations supplémentaires.
En outre, rappelons que ces phases d’entraînement font appel à de nombreux processeurs dédiés (grilles de calcul, ferme de calcul), ainsi qu’à des centres de données qui stockent les bases d’apprentissage, et à des infrastructures réseau qui permettent d’acheminer les données vers les centres de calcul. Ces travaux s’appuient donc sur du matériel dont la fabrication et la quantité ont également un impact environnemental très élevé.
Mesurer l’empreinte carbone due à la consommation d’un programme
L’exécution d’un programme d’IA entraîne plusieurs types de consommation énergétique :
- consommation GPU, CPU et DRAM. Ce sont ces consommations qui sont le plus souvent utilisées pour estimer la consommation ou l’empreinte d’un programme d’IA.
- consommation supplémentaire des serveurs (carte mère, alimentation, ventilateurs…)
- consommation des équipements permettant d’utiliser les serveurs : équipements informatiques supplémentaires (réseau, écrans…), et équipements autres du data center, en particulier baies de stockage et climatisation.
Afin de mesurer la consommation, il est parfois possible d’effectuer une mesure directe avec un wattmètre ou un PDU (Hardware-based power measurement), mais ce n’est généralement pas possible, et des indicateurs sont alors utilisés pour estimer la consommation réelle (Software-based power measurement).
Dans les outils présentés dans la suite, la consommation est estimée par une variante de la formule :
Etotal = PUE x Σ Eressource
avec :
- Eressource consommation ressource pour le processus, les ressources prises en compte étant généralement les suivantes : CPU, GPU et DRAM
- PUE efficacité énergétique du datacenter (consommation électrique de l’ensemble du datacenter divisée par la consommation électrique des équipements informatiques)
puis l’équivalent CO2 par :
CO2eq = Etotal x FE
avec: FE facteur d’émission de l’électricité, qui permet de convertir une consommation d’électricité en émissions de gaz à effet de serre correspondante, et dépend donc du mix énergétique du lieu où se situe le datacenter et de la période à laquelle le programme est lancé.
Nous listons dans la suite plusieurs outils qui peuvent être utilisés, et quelques indications sur leur fonctionnement. Nous n’indiquons que les outils qui indiquent à la fois la consommation d’électricité et l’empreinte carbone associée.
Outils en ligne
- Green Algorithms (Lannelongue et al.) est un outil en ligne qui permet de calculer la consommation d’énergie et l’empreinte carbone associée, en fournissant un certain nombre d’informations sur l’expérience : durée d’exécution, nombre de coeurs, utilisation de la mémoire… À noter que cet outil permet également d’utiliser un « pragmatic scaling factor » qui permet de prendre en compte le fait que le programme est généralement exécuté un certain nombre de fois notamment pour régler les hyperparamètres.
- ML CO2 Impact (Lacoste et al.) est un outil en ligne qui permet de calculer la consommation d’énergie et l’empreinte carbone associée à partie des informations suivantes : type de matériel, durée d’exécution, fournisseur des équipements et localisation.
Les outils en ligne sont a priori moins précis que les librairies intégrées dans le code. En revanche, ils permettront d’estimer l’impact a priori (en fonction de la durée d’exécution) d’une expérience.
Outils téléchargeables
- Experiment impact tracker (Henderson et al.) est une librairie python qui calcule la consommation d’énergie à partir des informations GPU, CPU et DRAM.
- Carbon tracker (Anthony et al.) est également une librairie python qui calcule la consommation d’énergie à partir des informations GPU, CPU et DRAM. Par rapport à impact tracker, il permet d’arrêter l’entraînement d’une expérience quand un coût environnemental fixé est dépassé.
- CodeCarbon est une troisième librairie python fondée sur le même principe que les précédentes.
Quelques exemples d’évaluation
Plusieurs travaux de recherche se sont intéressés à l’estimation du coût énergétique de ces techniques et à la comparaison du coût de différentes configurations. Parmi les premiers travaux sur ce thème :
- (Li et al, 2016) sont partis du constat que les réseaux de neurones convolutionnels (CNN) étaient très utilisés en classification d’images et détection d’objets depuis quelques années pour leur grande précision, mais sont très énergivores. Ils ont donc souhaité calculer les différences de consommation d’énergie en fonction de la configuration, et ont montré que la consommation était très variable.
- (Strubell et al., 2019) ont fait une étude de cas dans le domaine du traitement automatique des langues (Natural Language Processing) en comparant 4 modèles de l’état de l’art. Ils ont estimé le coût énergétique en prenant en compte les consommations mémoire, processeur et processeur graphique du centre de calcul et ont montré que les consommations énergétiques étaient très importantes et très variables en fonction du modèle. Les émissions pour l’entraînement d’un modèle allaient en effet de 18kg eqCO2 à 284T eq CO2. Le modèle le plus couramment utilisé, sans paramétrage spécifique, émettait 652kg eqCO2, soit environ un aller Paris-Hong Kong en avion, ou 2500km en voiture… Même si ces résultats ont récemment été discutés (Patterson et al., 2021) et qu’ils correspondent à des expériences aux États-Unis (et donc avec un mix énergétique américain), ils ont permis de lancer la discussion sur le coût énergétique des expériences de traitement automatique des langues.
Bonnes pratiques
Étant donné le coût énergétique de ces techniques, il semblerait utile :
- de poursuivre les travaux théoriques et techniques permettant de réduire l’impact de ces méthodes, par exemple en améliorant les librairies utilisables et en poursuivant les travaux théoriques permettant de mieux comprendre le fonctionnement des réseaux, ce qui permet de diminuer drastiquement les phases de paramétrage ;
- d’évaluer systématiquement l’impact des expériences dans les publications de recherche, en plus du temps de calcul qui est généralement indiqué, ce qui permettrait de promouvoir une vision plus inclusive de la performance (voir aussi Schwartz et al., 2019 à ce sujet) ;
- d’avoir une mesure d’impact intégrée dans les outils et centre de calculs ;
- d’utiliser des centres de calcul avec un faible impact environnemental ;
- et pour tous les points cités précédemment, en faisant attention aux effets rebond : l’amélioration des performances ne doit pas pousser à faire plus de calculs ;
- d’avoir une utilisation raisonnée de ces techniques, par exemple en faisant une analyse coût/bénéfice par rapport à d’autres méthodes.
Références
- Anthony, Lasse F. Wolff, et al. « Carbontracker: Tracking and Predicting the Carbon Footprint of Training Deep Learning Models ». ArXiv:2007.03051 [Cs, Eess, Stat], juillet 2020, http://arxiv.org/abs/2007.03051.
- García-Martín, Eva, et al. « Estimation of Energy Consumption in Machine Learning ». Journal of Parallel and Distributed Computing, vol. 134, décembre 2019, p. 75‑88, doi:10.1016/j.jpdc.2019.07.007.
- Henderson, Peter, et al. « Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning ». ArXiv:2002.05651 [Cs], 2020, http://arxiv.org/abs/2002.05651.
- Lacoste, Alexandre, et al. « Quantifying the Carbon Emissions of Machine Learning ». ArXiv:1910.09700 [Cs], novembre 2019, http://arxiv.org/abs/1910.09700.
- Lannelongue, Loïc, et al. Green Algorithms: Quantifying the Carbon Emissions of Computation. 2020, p. 18.
- Li, Da, et al. « Evaluating the Energy Efficiency of Deep Convolutional Neural Networks on CPUs and GPUs ». 2016 IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom) (BDCloud-SocialCom-SustainCom), IEEE, 2016, p. 477‑84, doi:10.1109/BDCloud-SocialCom-SustainCom.2016.76.
-
Patterson, David, et al. « Carbon Emissions and Large Neural Network Training ». arXiv:2104.10350 [cs], avril 2021, http://arxiv.org/abs/2104.10350.
- Strubell, Emma, et al. « Energy and Policy Considerations for Deep Learning in NLP ». ArXiv:1906.02243 [Cs], juin 2019, http://arxiv.org/abs/1906.02243.
voir aussi :
- Cours sur l’impact “Impact du numérique et de l’IA sur l’environnement”, CentraleSupelec, Anne-Laure Ligozat, 18 mars 2021
- La librairie zotero du groupe de travail IA d’EcoInfo